
研究紹介

はじめに
権藤研究室では、コンピュータ・ソフトウェアの不具合 (バグ) をなくすためのツールをおもに研究しています。
バグのないソフトウェアを作るのはなぜそれほど難しいのでしょうか。これは「絶対に事故を起こさない自動車」を作るのに似ています。自動車の運転は複雑な操作であり、時にはドライバー (ユーザ) は設計者も想定していなかった運転 (使い方) をすることがあります。また、機械そのものの複雑さ自身に起因する問題もあります。たとえば、トヨタ自動車の車は1台あたり30,000点を超える部品から成り立っていますが [1]、それぞれの部品は異なる理由により、異なるタイミングで故障します。
コンピュータ・ソフトウェアは、おそらく人類がこれまで構築してきたものの中でも最も複雑な「機械」の一種です。たとえば、Android スマートフォンに搭載されているソフトウェアは合計 1000万行を超えるソースコードで書かれており [2]、最近の自動車に搭載されているソフトウェアはその数十倍の規模になっています [3]。いっぽう、1970年に書かれた最初の UNIX バージョン 1 のソースコードはわずか 2,500行でした [4]。つまり、過去50年間でコンピュータ・ソフトウェアの規模は 数万倍〜数十万倍に膨れあがっていることになります。

しかし、ソフトウェアのこれほどの複雑化にもかかわらず、そのコードを書いているのはあいかわらず生身の人間です。学部生のみなさんが実際に授業の課題などで書くコードは 1000行にも満たないかもしれませんが、現在の一般的なソフトウェアは、ごく簡単なものでさえ 1万行から10万行程度の規模になるのが普通です。これほどの複雑さに人類はどうやって対処しているのでしょうか。結論からいえば、あまりうまく対処できていません。現在のソフトウェアはまだ不具合が多く、複雑でわかりにくく、そして作るのに時間がかかります。そして、一旦不具合が発生すると、その原因をつきとめてデバッグするのは非常に困難な作業であり、それによって社会に多くの被害が出ることも少なくありません [5] [6]。権藤研究室では、こうした人間の負担を少しでも軽くするための手法やツールを研究しています。
研究テーマ (抜粋)
権藤研究室のメンバーがこれまで行ってきた研究テーマの一部を紹介します。
機械学習を用いた耐久テスト (fuzzing) の改良
発表論文
- Yuma Jitsunari and Yoshitaka Arahori,
Coverage-guided Learning-assisted Grammar-based Fuzzing

工学全般に言えることですが、潜在的に起こりうる事態すべてに前もって対処することは不可能です。ソフトウェアにおいても同様で、プログラムに対する入力にはほぼ無限の組み合せが存在するため、複雑なソフトウェアの挙動をあらかじめすべて予測することはできません。(型システムや数理論理を使って特定の動作を保証できるようなコードも存在しますが、そのようなソフトウェアはまだ少ないのが現状です。) このための対処方法のひとつとして、プログラムがなるべく「想定していなそうな」入力を外部からランダムに与えて挙動を観察するという手法 (fuzzing、ファジング) があります。しかし、これは単にランダムな入力を与えればよいというものではありません。たとえば、プログラムの内部が以下のようになっていたとすると:
int parse(char *s, int i, int n) {
if (i+3 < n &&
s[i] == 'd' &&
s[i+1] == 'e' &&
s[i+2] == 'f' &&
isdigit(s[i+3])) {
...
}
}
上の「...」の中を実行させるためには、引数 s と i と n
に正しい値を与える必要があります。これらをランダムな試行によって発見するのは現実的ではありません。本研究は、機械学習とあらかじめ用意された入力データを使って、「なるべく多くの部分を実行するような新しい入力データ」を自動的に生成しようというものです。本研究では複雑なPDFパーザを実行させ、そのコード中で実際に実行された部分を外部から観察して、よいデータを生成するための規則を学習しました。これを使うことにより
既存のデータよりもよりよい入力を生成できることが確認されました。

ソースコードにおける仕様追跡の補助
発表論文
- Katsuhiko Gondow, Yoshitaka Arahori, Koji Yamamoto, Masahiro Fukuyori and Riyuuichi Umekawa,
TCC (Tracer-Carrying Code): a Hash-based Pinpointable Traceability Tool using Copy & Paste

実際のソフトウェア開発は、数百から数千項目にわたる外部仕様との格闘です。たとえば電子メールを扱うソフトウェアを書く場合、開発者は RFC 5321 や RFC 5322 といった文書に書かれている膨大な仕様を理解し、これらを正しく実装する必要があります。問題は、ソフトウェアの規模が大きくなるにつれて、ソースコード上のどの部分がどの仕様に対応しているか (traceability, トレーサビリティ) を把握することが難しくなることです。そこで本研究ではこれらの外部仕様をソースコードの中にリンクとして含めた「TCC (Tracer-Carrying Code)」というアイデアを提案し、開発者が仕様へのリンクを簡単に埋め込めるよう、既存のツール (エディタ, ブラウザ, PDFビューア等) を拡張しました。また、これらのツールを使って簡単な iOS アプリを開発することで、その有用性を確認しました。

データ競合の自動検出
発表論文
- Yoshitaka Sakurai, Yoshitaka Arahori and Katsuhiko Gondow,
Skew-Aware Parallel Race Detection

通常の手続き型言語におけるプログラムは、実行する順序があらかじめわかっているのが普通です。ところが、複数のコードを同時並列的に実行するマルチスレッド環境下ではこれが成立せず、予期せぬバグが発生することがあります。たとえば以下のコードを考えてみましょう:
int a = 0;
f() { a = a + 1; }
g() { a = a + 2; }
main() {
f()とg()を各スレッドで同時に実行。
printf("%d\n", a);
}
関数 f() と g() の実行が終わったあと、最後に表示される変数 a の値は 3 になるでしょうか? 実はそうとは限らないのです。これは、a = a + 1; という処理が、実際には
関数f
- 変数
aの値を読み出す -
1を加える - 変数
aに値を書き込む
関数g
- 変数
aの値を読み出す -
2を加える - 変数
aに値を書き込む
という3つの操作から成り立っているためです。関数 f() と g() は並列的に実行されているため、f1, g1, f2, g2, f3, g3 の各操作がどのような順序で起こるかは正確にはわかりません。もし f3 の操作が起きる直前に g3 が完了したとすると、f3 は正しい値を上書きしてしまい、a の値は
1 のままになってしまいます。
このようなバグ (race condition, データ競合状態) はつねに発生するとは限らないため、非常に厄介です。そのため、このようなバグを実行時の検査によって自動検出する研究がさかんに行われています。この際、問題となるのは検査の効率です。実行時の検査にかかる時間が長いと、プログラムそのものの実行時間が長くなってしまいます。本研究ではそのようなアルゴリズムのひとつである Parallel FastTrack の高速化手法を提案しました。具体的には、Parallel FastTrack が特定の状況で非常に遅くなるケースを特定し、それを解消するアルゴリズムを設計し、その有用性を確認しました。
メモリリークの自動検出
発表論文
- 小泉 雄太, 荒堀 喜貴, 権藤 克彦
「高脅威メモリリークのバイナリレベル動的検出法」

すべてのプログラムは実行時にある程度のメモリ領域を使用します。C や C++ など、効率を重視する言語では、メモリ管理はある程度までプログラムを書く側に任されていますが、これはバグの原因になりえます。たとえば以下の関数 f() を見てみましょう:
f() {
char *p = malloc(100); /* メモリ領域を確保 */
if (read(p, 100) != 0) {
return; /* エラー */
}
print(p);
free(p); /* メモリ領域を解放 */
}
ここでは malloc() 関数で 100バイトぶんのメモリ領域を確保し、read() 関数でそこにデータを読み込み、最後に free() でそれを解放します。ところが、read() でエラーが発生したときには free() を呼ばずに 関数から return
してしまいます。これが「メモリリーク」と呼ばれる現象です。メモリリークは少量であれば問題ありませんが、もしこの関数 f() がループ中で繰り返し呼ばれるようなプログラムでは、利用可能なメモリは時間とともに減っていき、ついにはメモリ不足のためにプロセスがクラッシュしてしまいます。
本研究では 計装 (instrumentation) というテクニックを用いて実行中のプログラムの挙動を外部から観察し、上の例にあるようなループ中で繰り返し発生する「危険な」メモリリークを自動的に検出する手法を開発しました。これを実際のプログラムに適用し、いくつかの危険なリークを現実的な時間で発見できることを確認しました。

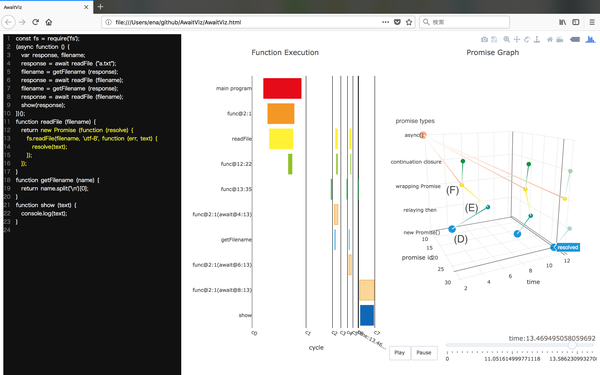
JavaScriptコードにおけるasync/awaitの視覚化
発表論文
- Ena Tominaga, Yoshitaka Arahori and Katsuhiko Gondow,
AwaitViz: a Visualizer of JavaScript’s async/await execution order

JavaScript プログラムは、並列な処理を実現するのにスレッドを用いた方法ではなく、イベント駆動によるコールバックを使っています。たとえば Java であれば
fp = new FileReader(path); // ファイルを開く
int data = fp.read(); // 読み込む
System.out.println(data); // 表示のようにするところを、Node.js では
fs.readFile(path, function (err, data) {
// ファイルが読み込まれたときに呼ばれる。
if (err) throw err;
console.log(data); // 表示
});
のように書く、といった具合です。しかしコールバックを使ったコードは読みにくいため、 最近の JavaScript (ES7以降) では async/await という機構を導入しています。async/await 機構を使うと、上のプログラムは以下のように書くことができます。
(async () => {
var data = await readFile(path); // ファイルを読み込む
console.log(data); // 表示
})();
この方法では処理する順序のとおりにコードを書くことができます。ただし注意すべき点は、マルチスレッドの場合と同様、await を使った呼び出しをおこなうさい、間に別の処理が入る場合があり、プログラマの予期しなかった結果が起こることです。本研究では、この現象の理解を補助するため async/await
を使ったコードの実際の実行順序を視覚化するツール AwaitViz を開発し、このさい得られた知見をまとめました。
強化学習を用いたポインタ解析規則の自動生成
発表論文
- 湯川 涼太, 荒堀 喜貴, 権藤 克彦
「高品質なポインタ解析規則の自動生成に向けて」

プログラムの 静的解析 (static analysis) とは、プログラムのソースコードを実行前に検査し、そのプログラムに関する特性を発見することです。静的解析でよく行われる処理のひとつに、ポインタ解析があります。ポインタ解析とは、異なる変数に含まれるポインタ (参照) が 同じオブジェクトを指している (あるいは、指す可能性がある) かどうかを判定するもので、普通はソースコードを構文解析した結果に、あらかじめ作成したパターンをあてはめることにより判断します。
// Cの場合
char *p = malloc(100);
char *q = &(p[0]); /* p と q は同じメモリ領域を指す */// JavaScriptの場合
var b = new Object();
var a = b; // a と b は同じオブジェクトを指す問題は、このようなパターンを各プログラミング言語ごとに人手で作成するのは難しいということです。そこでこのパターンを、あらかじめ与えられたプログラムとそのポインタ解析の正解データをもとに自動で学習しようという試みがあります。本研究では「強化学習 (reinforcement learning)」という枠組みを使っています。これは機械学習の手法のひとつで、学習と同時に新しい問題も生成し、それをさらにまた学習に使うことで継続的に精度を上げていくという方法です。本研究では問題 (反例) 生成に使われていたアルゴリズムを改良し、より多くの情報を使って問題を生成することで、既存の学習アルゴリズムよりも高い精度をもつポインタ解析規則を学習できることを確認しました。